
Long Short-Term Memory: Từ Zero tới Hero với PyTorch (P1)
Cũng giống như con người, Mạng nơ ron hồi quy (Recurrent Neural Networks – RNNs) có thể rất hay quên. Cuộc đấu tranh với bộ nhớ ngắn hạn này khiến RNN dần mất hiệu quả trong hầu hết các tác vụ. Tuy nhiên, đừng băn khoăn, các mạng Bộ nhớ dài-ngắn (Long Short-Term Memory – LSTM) có bộ nhớ tuyệt vời và có thể nhớ những thông tin mà Vanilla RNN không thể làm được.
Các LSTM là một biến thể đặc biệt của RNN, do đó nắm bắt được các khái niệm xung quanh RNN sẽ hỗ trợ đáng kể cho bạn để hiểu về LSTM với PyTorch trong bài viết này.
Tóm tắt nhanh về RNNs
RNN xử lý dữ liệu đầu vào theo cách tuần tự, nơi mà thông tin từ đầu vào trước đó được xem xét khi tính toán đầu ra cho bước hiện tại. Điều này cho phép mạng nơ ron (Neural network) lưu trữ thông tin qua các bước khác nhau trong mạng (time steps) thay vì giữ tất cả các đầu vào độc lập với nhau.

Tuy nhiên, một thiếu sót đáng kể gây khó khăn cho RNN truyền thống là vấn đề vanishing/exploding gradients. Vấn đề này phát sinh khi lan truyền ngược (back-propagation) qua RNN trong quá trình huấn luyện (training), đặc biệt là đối với các mạng có lớp (layers) sâu hơn. Gradients phải trải qua quá trình nhân ma trận liên tục trong quá trình lan truyền ngược do quy tắc chuỗi, làm cho gradients co lại theo cấp số nhân (hao hụt) hoặc mở rộng theo cấp số nhân (bùng nổ). Gradients thường sẽ có giá trị nhỏ dần khi đi xuống các layer thấp hơn. Kết quả là các cập nhật thực hiện bởi Gradient Descent không làm thay đổi nhiều weights của các layer đó, khiến chúng không thể hội tụ và Deep Neural Network (DNN) sẽ không thu được kết quả tốt. Hiện tượng này được gọi là Vanishing Gradients. Trong nhiều trường hợp khác, gradients có thể có giá trị lớn hơn trong quá trình backpropagation, khiến một số layers có giá trị cập nhật cho weights quá lớn khiến chúng phân kỳ (phân rã), tất nhiên DNN cũng sẽ không có kết quả như mong muốn. Hiện tượng này được gọi là Exploding Gradients, và thường gặp khi sử dụng Recurrent Neural Networks (RNNs).
Gradients
Gradient thực chất chính là đạo hàm của một hàm số được dùng để biểu diễn tỷ lệ thay đổi (sự biến thiên) của một hàm số tại một điểm nào đó. Nó là một vector với hai tính chất chính sau:
- Hướng của vector sẽ hướng theo chiều tăng của hàm.
- Giá trị của Gradient sẽ là 0 tại các điểm cực tiểu (local minimum) hay cực đại (local maximum).
Do những vấn đề này, với các bước phụ thuộc càng xa thì việc học sẽ càng khó khăn hơn vì sẽ xuất hiện vấn đề hao hụt/bùng nổ (vanishing/exploding) của đạo hàm. Có một vài phương pháp được đề xuất để giải quyết vấn đề này và các kiểu mạng RNN hiện nay đã được thiết kế để triệt tiêu bớt chúng như LSTM chẳng hạn.
Vậy, LSTM là gì? và LSTM với PyTorch như thế nào?
Trong khi LSTM là một loại RNN và hoạt động tương tự như RNN truyền thống, thì cơ chế Gating của nó là thứ tạo ra sự khác biệt. Tính năng này giải quyết vấn đề bộ nhớ ngắn hạn “short-term memory” của RNNs.
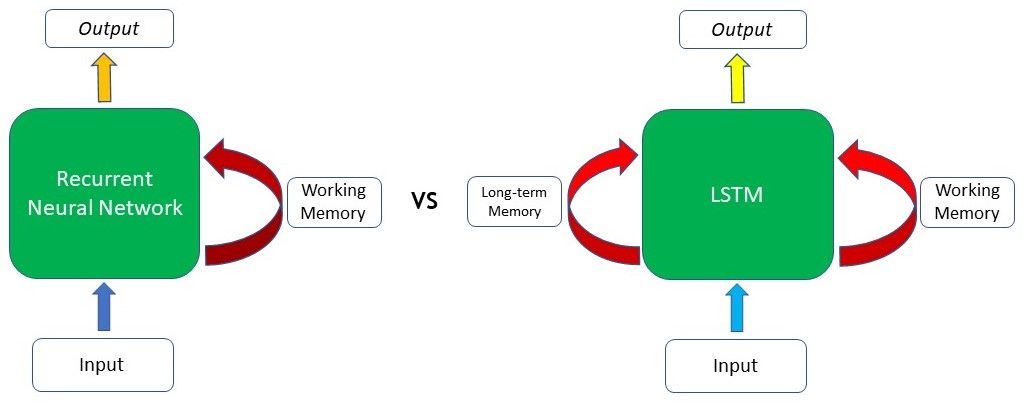
Như chúng ta có thể thấy từ hình ảnh, sự khác biệt chủ yếu nằm ở khả năng của LSTM khi lưu trữ được “long-term memory”. Điều này đặc biệt quan trọng trong phần lớn bài toán Xử lý ngôn ngữ tự nhiên (NLP) hoặc xử lý thông tin dạng chuỗi (time-series). Ví dụ: giả sử chúng tôi một network text (văn bản) dựa trên một số đầu vào (input) được cung cấp. Ở phần đầu của văn bản, người ta đã đề cập rằng người viết có một chú chó tên là Cliff “dog named Cliff”. Sau một vài câu khác mà không đề cập đến pet or dog, người viết lại đưa thú cưng (pet) của mình ra và giờ mô hình phải tạo ra từ tiếp theo thành “However, Cliff, my pet ____”. Vì từ thú cưng (pet) xuất hiện ngay trước chỗ trống, RNN có thể suy luận rằng từ tiếp theo có thể sẽ là một con vật mà có thể được coi như là thú cưng.
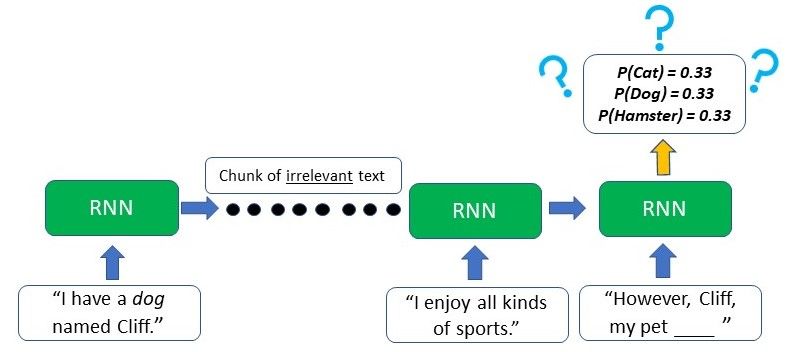
Tuy nhiên, do short-term memory, RNN truyền thống sẽ chỉ có thể sử dụng thông tin theo ngữ cảnh từ văn bản xuất hiện trong một vài câu gần nhất – hoàn toàn không có ích gì. RNN không có manh mối nào về việc con vật cưng đó là con nào vì những thông tin liên quan từ ban đầu đoạn văn bản đó đã bị biến mất (không được nhớ nữa).
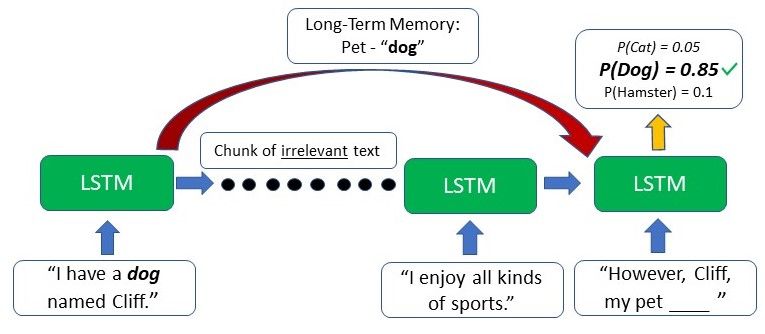
Ngược lại, LSTM có thể giữ lại thông tin trước đó mà người viết có một con pet dog và điều này sẽ hỗ trợ mô hình chọn “the dog” khi mà viết tiếp văn bản tại thời điểm đó bởi vì thông tin theo ngữ cảnh từ đầu đã được nhớ.
Hoạt động bên trong của LSTM với PyTorch
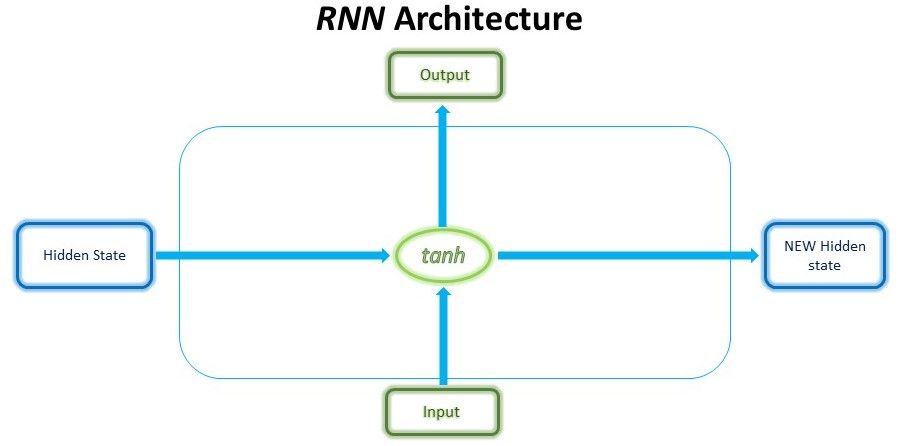
Mấu chốt của LSTM nằm ở cơ chế gating với mỗi tế bào LSTM. Tuy nhiên, trong tế bào RNN thông thường, đầu vào (input) tại bước t và trạng thái ẩn phía trước (hidden state) t-1 được tính toán qua “tanh” (như trong hình) để ra được trạng thái ẩn mới và đầu ra (a new hidden state and output).
Trong khi đó LSTM có cấu trúc phức tạp hơn một chút. Về cơ bản mô hình của LSTM không khác mô hình truyền thống của RNN, nhưng chúng sử dụng hàm tính toán khác ở các trạng thái ẩn. Bộ nhớ của LSTM được gọi là tế bào (Cell) và bạn có thể tưởng tượng rằng chúng là các hộp đen nhận đầu vào là trạng thái phía trước h(t−1) và đầu vào hiện tại x(t). Bên trong hộp đen này sẽ tự quyết định cái gì cần phải nhớ và cái gì sẽ xoá đi. Sau đó, chúng sẽ kết hợp với trạng thái phía trước, nhớ hiện tại và đầu vào hiện tại (the short-term memory from the previous cell (similar to hidden states in RNNs), lastly the long-term memory and the current input data, ). Vì vậy mà ta ta có thể truy xuất được quan hệ của các từ phụ thuộc xa nhau rất hiệu quả.
Bộ nhớ ngắn hạn thường được gọi là trạng thái ẩn và bộ nhớ dài hạn thường được gọi là trạng thái tế bào.
Những cổng (gates) này có thể được coi giống như máy lọc nước. Vai trò của các cổng này được cho là loại bỏ có chọn lọc bất kỳ thông tin không liên quan nào, tương tự như cách máy lọc nước loại bỏ tạp chất. Đồng thời, chỉ có nước và các chất dinh dưỡng có lợi có thể đi qua các máy lọc này, giống như cách các cổng chỉ giữ thông tin hữu ích. Tất nhiên, các cổng này cần được đào tạo để lọc chính xác những gì hữu ích và những gì không.

Các cổng này được gọi là Cổng đầu vào (Input Gate), Cổng quên (Forget Gate) và Cổng đầu ra (Output Gate). Có nhiều biến thể cho tên của các cổng này; tuy nhiên, tính toán và hoạt động của các cổng này hầu hết giống nhau.
Hãy cùng nhau đi qua các cơ chế của các cổng này.
Input Gate
Cổng đầu vào quyết định thông tin mới nào sẽ được lưu trữ trong long-term memory. Nó chỉ hoạt động với thông tin từ đầu vào hiện tại và short-term memory từ trước đó. Vì vậy, cần phải lọc ra thông tin hữu ích và thông tin không hữu ích từ những biến đó.

Forget Gate
Forget Gate quyết định thông tin nào từ long-term memory nên được lưu giữ hay loại bỏ. Điều này được thực hiện bằng cách nhân long-term memory sắp tới với một forget vector được tạo ra bởi đầu vào hiện tại và short-term memory sắp tới.

Output Gate
Cổng đầu ra sẽ lấy đầu vào hiện tại, short-term memory trước đó và long-term memory mới được tính toán để tạo ra new short-term memory/hidden state (bộ nhớ ngắn hạn mới/trạng thái ẩn) và được chuyển tới tế bào (cell) ở bước tiếp theo. Đầu ra hiện tại cũng có thể được rút ra từ trạng thái ẩn này.

Hy vọng sau bài viết này, độc giả sẽ có cái nhìn tổng quan về Long Short-Term Memory, và PyTorch. Hiện nay, iRender mang tới cho khách hàng dịch vụ GPU Cloud for AI/DL – cung cấp hiệu suất máy tính với hàng ngàn CPUs và GPUs mạnh mẽ, đồng thời hỗ trợ Deep Learning Framework phổ biến như PyTorch. Chúng tôi có những dòng cấu hình máy chuyên nghiệp phục vụ cho AI Inference, AI Training, Deep Learning, VR/AR…Với kiến trúc Turing: 6/12 x RTX 2080Ti, 11GB vRAM, kiến trúc Pascal: 6/12 x NVIDIA TITAN Xp, 12GB vRam.
Hãy đăng ký tại đây để sử dụng dịch vụ của chúng tôi.
Nguồn: AI Global & Hai's Blog
